
Have you used your application or search engine to understand the underlying meaning behind your query? If yes, the solution to this requirement is through Semantic Search. A couple of years ago, a simple keyword search would have yielded search results matching just the keywords. We call it ‘lexical search’. Today, we can have machines and applications understand the semantics behind a query through Natural Language Processing (NLP). The credit goes to the Artificial Intelligence revolution.
Let’s say you search the nursery rhyme, ‘Hey Diddle Diddle’ on Google. And the search results will return both lexical and semantic instances of it. The former is an example of computational information retrieval below semantic search. So, we can say that “Semantic search describes a search engine’s attempt to generate the most accurate Search Engine Results Page (SERP) results possible by understanding based on searcher intent, query context, and the relationship between words.“
Through the superset of machine learning, we have the following abilities today:
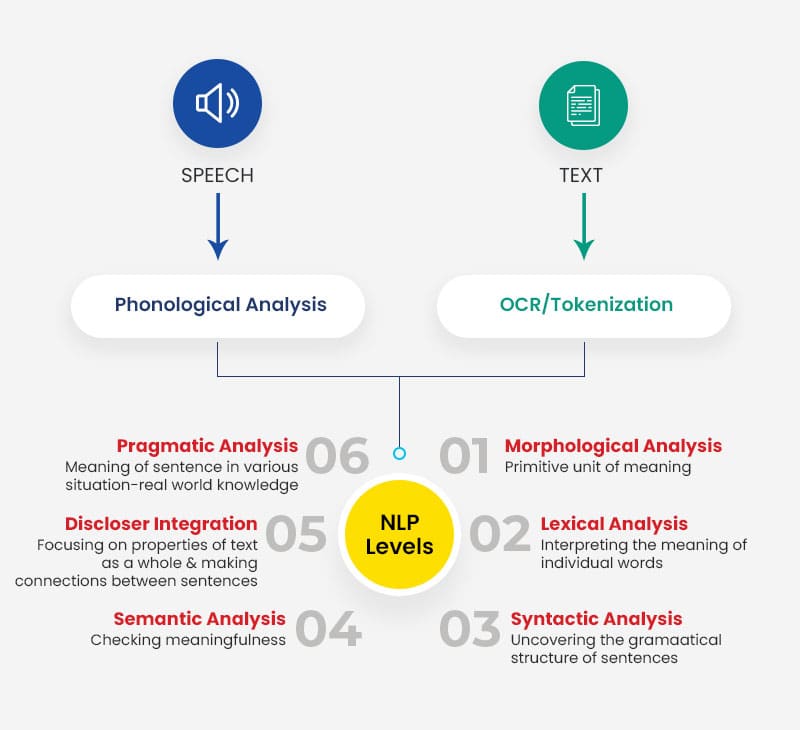
Natural Language Processing (NLP): It is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language. It can be further divided into 3 fields:
The above machines help to ‘comprehend’ both intent and context of human communication. Imagine the positive impact that this emerging technological paradigm has had on global trade, academics, scientific research, and culture. After all, there are over 6,500 human natural languages all over the world!
The best part of this technology is that both speech and text can use it. However, we would stick to the dynamics of semantic search alone. It involves a pre-processing data stage called text processing. This allows the understanding and processing of large amounts of text data. It is the process of analyzing textual data into a computer-readable format for machine learning algorithms.
A language model is a tool to incorporate concise and abundant information reusable in an out-of-sample context by calculating a probability distribution over words or sequences of words.
The problem of NLP cannot be explained without citing BERT (Bidirectional Encoder Representations from Transformers) as an example of a state-of-the-art pre-trained language model. The bidirectional encoder representations from transformers can answer more accurate and relevant results for semantic search using NLP. Jacob Devlin created a well-known state-of-the-art language model in 2018. And Google leveraged in 2019 to understand user searches.
There are many open-source frameworks for solving NLP problems such as NLTK, GPT3, and spaCey. We at INT. use those frameworks for engineering NLP-driven software.
GPT3 (Generative Pre-trained Transformer- think GAN of NLP) was a wonder framework released in 2020 by OpenAI. It has the power to thrill and scare people due to its accuracy in mimicking human natural language. It used a transformer, which is a deep learning model that adopts the mechanism of self-attention, differentially weighting the significance of each part of the input data. NLP and computer vision (CV) primarily use the GPT3 framework. Its ability to differentially weight features works out terrifically for us as the model can discern different words in a sample. Also, it can assign probabilities of them occurring in the past, present, and future.
Language models such as BERT need a truly humongous amount of data in the targeted language to fine-tune its general understanding of the language. Data engineering is an absolute need for the accuracy of a language model. Crowdsourcing is one such strategy to get abundant data.
The other way is to have an application/algorithm crawl through targetted or available resources on the internet.
Lastly, companies specializing in the required data for NLP can provide data for purchasing.